 Thu Feb 6 17:19:12 2020, Dinko Ferencek, Reception test, RT for 6 modules: 1551, 1552, 1553, 1554, 1555, 1556 Thu Feb 6 17:19:12 2020, Dinko Ferencek, Reception test, RT for 6 modules: 1551, 1552, 1553, 1554, 1555, 1556
|
Today reception test was run for 6 modules and looks OK for all module. The modules were graded as follows:
1551: A
1552: A
1553: B (Electrical grade B)
1554: A
1555: B (IV grade B)
1556: B (IV grade B)
Protective caps were glued to these modules. |
|
Wed Feb 12 15:40:13 2020, Dinko Ferencek, Reception test, RT for 3 modules: 1569, 1570, 1571; 1572 bad
|
1569: Grade A
1570: Grade A
1571: Grade B, I > 2 uA (3.09 uA)
1572 from the same batch of 4 assembled modules was not programmable and was not run through the reception test. |
|
Fri Feb 14 14:40:59 2020, Dinko Ferencek, Reception test, RT for 2 modules: 1578, 1580
|
1579: Grade A
1580: Grade A |
|
Tue Apr 14 17:29:46 2020, Andrey Starodumov, General, ROC4 or ROC12 defects
|
Starting from M1650 almost every module has a cluster of dead pixels or broken bump bonds on
ROC4 or (more often) ROC12. The number of defects varied from 20 to 40.
It's almost excluded that such damage is made at PSI, since both of us: Silvan and me, first time connected the cable
to the module.
It would be interesting to check whether these bare modules arrived all together. |
|
Fri Jan 24 18:16:09 2020, Dinko Ferencek, Module assembly, Protective cap gluing
|
| Today I additionally practiced protective cap gluing by adding a protective cap to module M1536. |
|
Fri Feb 14 14:05:16 2020, Dinko Ferencek, Module assembly, Production yield so far
|
Of 41 modules produced and tested so far (1536-1576), 6 modules were found to be bad before or during the reception test, 5 were graded C after the full qualification (one of which is possibly C*) and the remaining 30 modules were graded B (of which 4 were manually regraded from C to B).
The overall yield for good modules (A+B/Total) produced so far is (30/41)=73% |
|
Tue May 26 23:00:50 2020, Dinko Ferencek, Other, Problem with external disk filling up too quickly
|
The external hard disk (LaCie) used to back up the L1 replacement data completely filled up after transferring ~70 GB worth of data even though its capacity is 2 TB. The backup consists of copying all .tar files and the WebOutput/ subfolder from /home/l_tester/L1_DATA/ to /media/l_tester/LaCie/L1_DATA/ The corresponding rsync command is
rsync -avPSh --include="M????_*.tar" --include="WebOutput/***" --exclude="*" /home/l_tester/L1_DATA/ /media/l_tester/LaCie/L1_DATA/
It was discovered that /home/l_tester/L1_DATA/WebOutput/ was by mistake duplicated inside /media/l_tester/LaCie/L1_DATA/WebOutput/ However, this could still not explain the full disk.
The size of the tar files looked fine but /media/l_tester/LaCie/L1_DATA/WebOutput/ was 1.8 TB in size while /home/l_tester/L1_DATA/WebOutput/ was taking up only 50 GB and apart from the above-mentioned duplication, there was no other obvious duplication.
It turned out the file system on the external hard disk had a block size of 512 KB which is unusually large. This is typically set to 4 KB. In practice this meant that every file (and even folder), no matter how small, always occupied at least 512 KB on the disk. For example, I saw the following
l_tester@pc11366:~$ cd /media/l_tester/LaCie/
l_tester@pc11366:/media/l_tester/LaCie$ du -hs Warranty.pdf
512K Warranty.pdf
l_tester@pc11366:/media/l_tester/LaCie$ du -hs --apparent-size Warranty.pdf
94K Warranty.pdf
And in a case like ours, where there are a lot of subfolders and files, many of whom are small, a lot of disk space is effectively wasted.
The file system used on the external disk was exFAT. According to this page, the default block size (in the page they call it the cluster size) for the exFAT file system scales with the drive size and this is the likely reason why the size of 512 KB was used (however, 512 KB is still larger than the largest block size used by default). The main partition on the external disk was finally reformatted as follows
sudo mkfs.exfat -n LaCie -s 8 /dev/sdd2
which set the block size to 4 KB. |
|
Wed Oct 2 12:50:52 2019, Dinko Ferencek, Software, Problem with elComandante Keithley client during full qualification
|
Full qualification was attempted for M1532 on Oct. 1. After the second Fulltest at -20 C finished, the Keitley client crashed with the following error
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 147, in check_busy
self.check_busy(data[1:])
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 147, in check_busy
self.check_busy(data[1:])
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 147, in check_busy
self.check_busy(data[1:])
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 147, in check_busy
self.check_busy(data[1:])
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 147, in check_busy
self.check_busy(data[1:])
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 147, in check_busy
self.check_busy(data[1:])
File "/home/l_tester/L1_SW/elComandante/keithleyClient/keithleyInterface.py", line 139, in check_busy
if data[0] == '\x11': # XON
RuntimeError: maximum recursion depth exceeded in cmp
Because of this, the IV measurement never started (the main elComandante process was simply hanging and waiting for the Keithley client to report it's ready) and the main elComandante process had to be interrupted. |
 Sat Oct 5 22:59:58 2019, Dinko Ferencek, Software, Problem with elComandante Keithley client during full qualification Sat Oct 5 22:59:58 2019, Dinko Ferencek, Software, Problem with elComandante Keithley client during full qualification
|
| A new attempt to run the full qualification for M1532 was made on Friday, Oct. 4, but the Keithely client crashed with the same error message. This time we managed to see from log files that the crash happened after the first IV measurement at -20 C was complete and Keithley was reset to -150 V. Unfortunately, the log files were now saved for the test on Tuesday so we couldn't confirm that the crash occurred at the same point. |
Wed Feb 12 11:15:04 2020, Dinko Ferencek, Module grading, Problem with dead trimbits understood 14x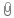
|
It was noticed that some modules are graded C because of typically just one ROC having a large number of dead trimbits. One example is ROC 10 in M1537
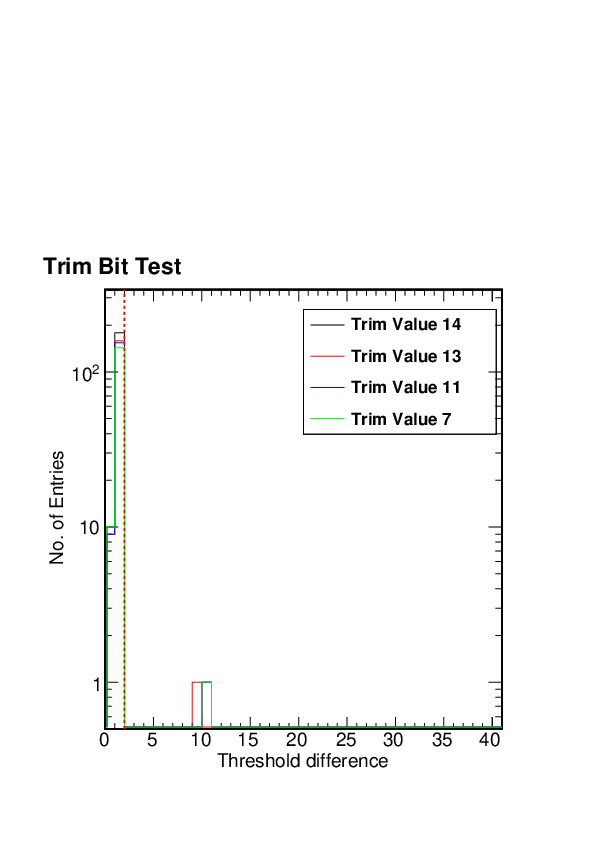

At the same time, for this same ROC the Vcal Threshold Trimmed distribution looks fine
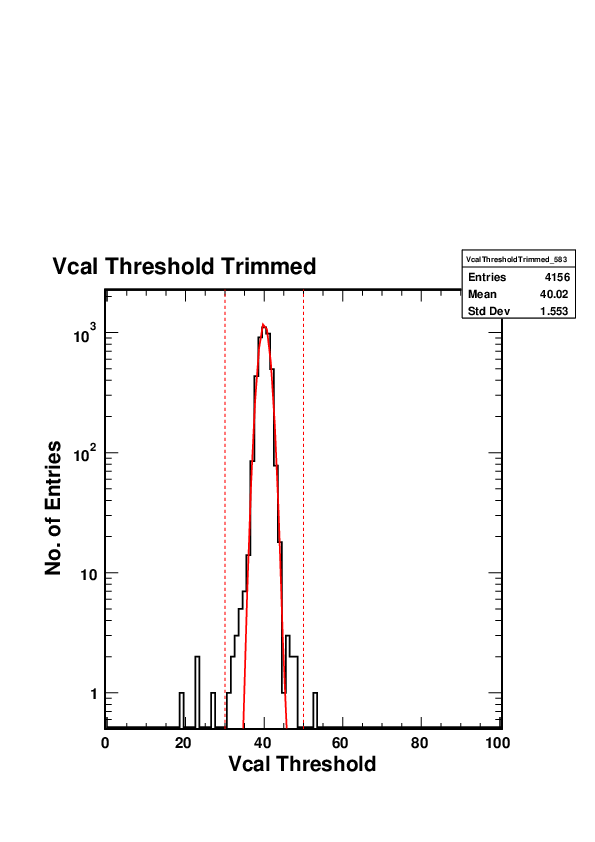

as well as the distribution of trim bits
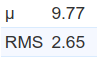
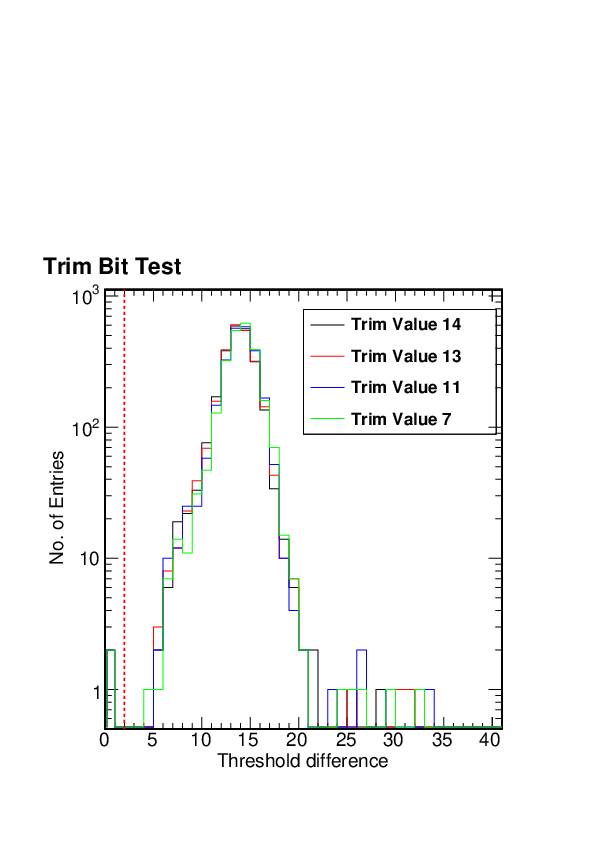
It turns out that the trim bit test is failing in this and other similar cases because of the tornado plot that is shifted up more than is typical

In the trim bit test code, the Vthrcomp was raised from 35 to 50 but for cases like this one, this is still not high enough. We therefore further increased the value of Vthrcomp to 70.
Grading procedure:
We will manually regrade to B all those modules graded as C due to dead trimbits provided the Vcal Threshold Trimmed distribution looks fine, the number of trimming problems is below the threshold for grade C (167), the distribution of trim bits looks reasonable, and they are not graded C for any other reason.
Side remark:
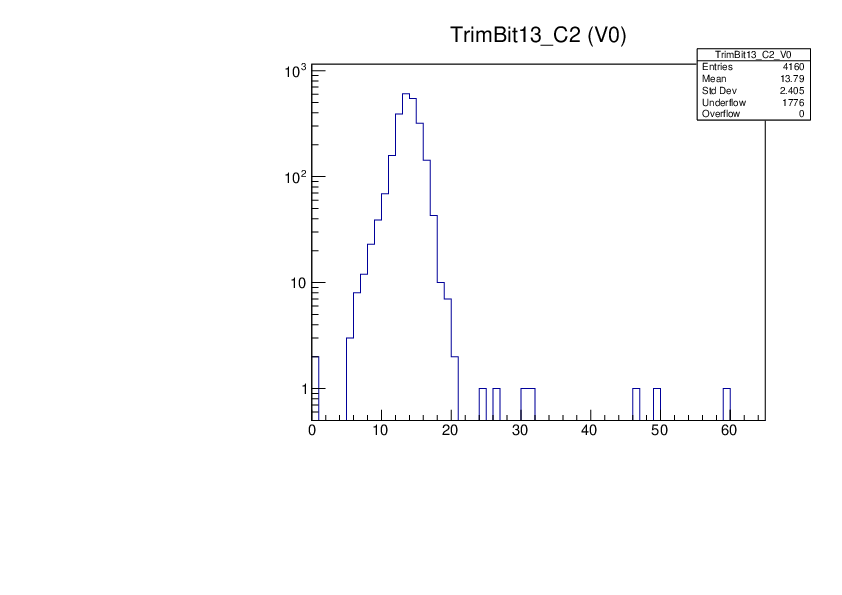
It should be noted that the Trim Bit Test distribution and the way the number of dead trimbits is counted will not always catch cases when the trim bit test algorithm failed. For instance, in the MoReWeb output for ROC 10 in M1537 one does not immediately see that there are many underflow entries
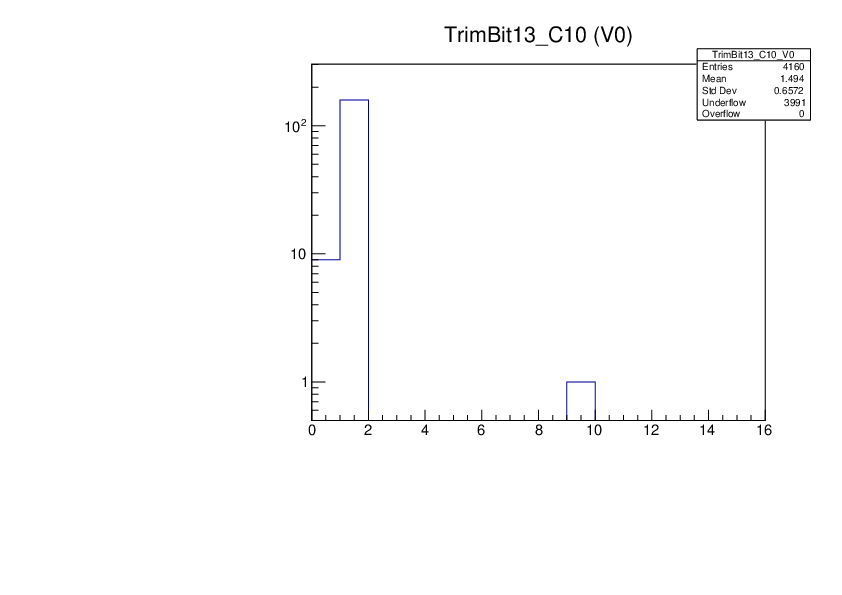
which arise from the fact that the untrimmed threshold used in the test is too might (Vthrcomp value too low) and Vcal that passes the threshold is not found and left at the default value of 0
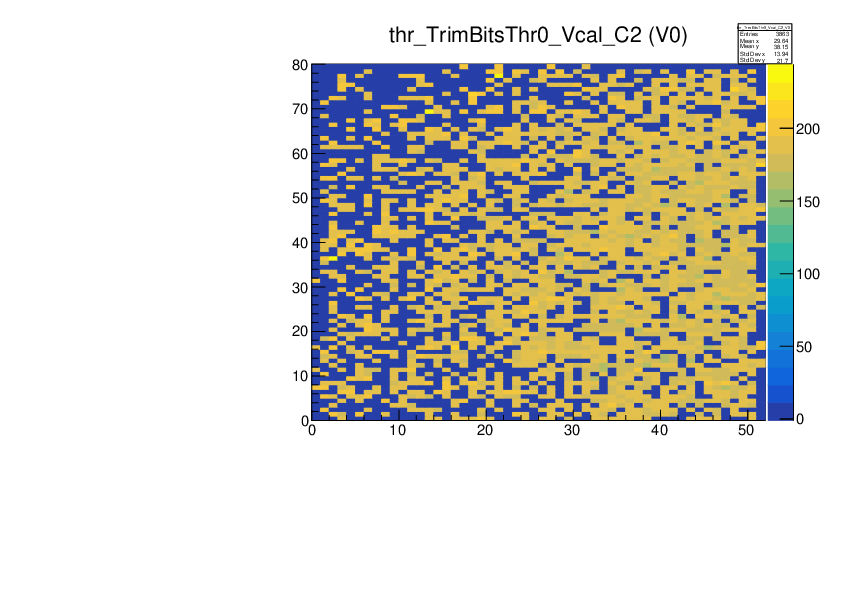
This problem of not spotting the algorithmic failure is particularly severe in the case of ROC 2 of the same module M1537 where it goes completely unnoticed in the summary table
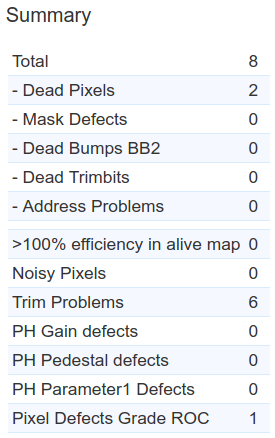
it is very hard to spot from the plot (because there is no statistics box showing the underflow)
but the problem is there for a large number of pixels
Even from the tornado plot one would not expect problems
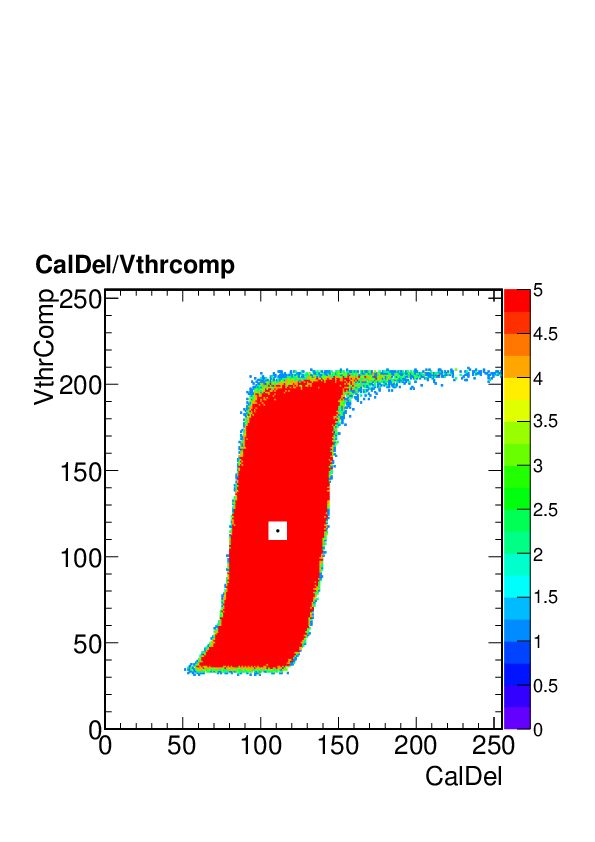
but this tornado is for one particular pixel (column 12, row 22) and there is no guarantee that for other pixels the trim bit test won't fail. |
|
Mon Mar 16 15:20:03 2020, Matej Roguljic, PhQualification, PhQualification on 16.3.
|
| PhQualification was run on modules M1561, M1564, M1565, M1566. |
|
Mon Mar 16 10:05:23 2020, Matej Roguljic, Software, PhQualification change
|
| Urs made a change in pXar, in the PhOptimization algorithm. One of the changes is in the testParameters.dat where vcalhigh is set to 100 instead of 255. This was implemented on the PC used to run full qualification. A separate procedure for elComandante was created, "PhQualification.ini", which runs pretest, pixelalive, trimming, ph and gainpedestal. This procedure will need to be run on all the modules qualified before this change was made and later merged with previous full qualification results. |
|
Mon Mar 16 11:04:41 2020, Matej Roguljic, PhQualification, PhQualification 14.-15.3.
|
I ran PhQualification over the weekend with changes pulled from git (described here https://elrond.irb.hr/elog/Layer+1+Replacement/108).
14.3. M1554, M1555, M1556, M1557
First run included software changes, but I forgot to change the vcalhigh in testParameters.dat
The summary can be seen in ~/L1_SW/pxar/ana/T-20/VcalHigh255 (change T-20 to T+10 to see results for +10 degrees)
Second run was with vcalhigh 100.
The summary can be seen in ~/L1_SW/pxar/ana/T-20/Vcal100
15.3. M1558, M1559, M1560
I only ran 3 modules because DTB2 (WRE1O5) or its adapter was not working. Summary is in ~/L1_SW/pxar/ana/T-20/Vcal100
The full data from the tests are in ~/L1_DATA/MXXXX_PhQualification_... |
|
Wed Aug 7 18:01:06 2019, Matej Roguljic, Cold box tests, PhOptimization problem
|
| August 7 - we found out that PhOptimization algorithm starts leaking memory if it fails to find proper values. If running one setup, the test might go through. However, if multiple modules are tested in parallel and they all start leaking memory at the same time, the system will kill one testboard process (or two if necessary), causing the unlucky testboard(s) to get stuck (powered on, HV on, but no tests running) until they are reset. Current solution to this problem is to simply omit the PhOptimization if the fulltest procedure. We left gainPedestal, since it will use default Ph dac values. |
|
Sat Sep 12 23:45:56 2020, Dinko Ferencek, POS, POS configuration files created
|
pXar parameter files were converted to POS configuration files by executing the following commands on the lab PC at PSI
Step 1 (needs to be done only once, should be repeated only if there are changes in modules and/or their locations)
cd /home/l_tester/L1_SW/MoReWeb/scripts/
python queryModuleLocation.py -o module_locations.txt -f
Next, check that /home/l_tester/L1_DATA/POS_files/Folder_links/ is empty. If not, delete any folder links contained in it and run the following command
python prepareDataForPOS.py -i module_locations.txt -p /home/l_tester/L1_DATA/ -m /home/l_tester/L1_DATA/WebOutput/MoReWeb/FinalResults/REV001/R001/ -l /home/l_tester/L1_DATA/POS_files/Folder_links/
Step 2
cd /home/l_tester/L1_SW/pxar2POS/
for i in `cat /home/l_tester/L1_SW/MoReWeb/scripts/module_locations.txt | awk '{print $1}'`; do ./pxar2POS.py -m $i -T 50 -o /home/l_tester/L1_DATA/POS_files/Configuration_files/ -s /home/l_tester/L1_DATA/POS_files/Folder_links/ -p /home/l_tester/L1_SW/MoReWeb/scripts/module_locations.txt; done
The POS configuration files are located in /home/l_tester/L1_DATA/POS_files/Configuration_files/ |
|
Fri Nov 6 07:28:42 2020, danek kotlinski, POS, POS configuration files created
|
| Dinko Ferencek wrote: | pXar parameter files were converted to POS configuration files by executing the following commands on the lab PC at PSI
cd /home/l_tester/L1_SW/MoReWeb/scripts/
python queryModuleLocation.py -o module_locations.txt -f
python prepareDataForPOS.py -i module_locations.txt -p /home/l_tester/L1_DATA/ -m /home/l_tester/L1_DATA/WebOutput/MoReWeb/FinalResults/REV001/R001/ -l /home/l_tester/L1_DATA/POS_files/Folder_links/
cd /home/l_tester/L1_SW/pxar2POS/
for i in `cat /home/l_tester/L1_SW/MoReWeb/scripts/module_locations.txt | awk '{print $1}'`; do ./pxar2POS.py -m $i -T 50 -o /home/l_tester/L1_DATA/POS_files/Configuration_files/ -s /home/l_tester/L1_DATA/POS_files/Folder_links/ -p /home/l_tester/L1_SW/MoReWeb/scripts/module_locations.txt; done
The POS configuration files are located in /home/l_tester/L1_DATA/POS_files/Configuration_files/ |
Dinko
I have finally looked more closely at the file you have generated. They seem fine exept 2 points:
1) Some TBM settings (e.g. pkam related) differ from P5 values.
This is not a problem since we will have to adjust them anyway.
2) There is one DAC setting missing.
This is DAC number 13, between VcThr and PHOffset.
This is the tricky one because it has a different name in PXAR and P5 setup files.
DAC 13: PXAR-name = "vcolorbias" P5-name="VIbias_bus"
its value is fixed to 120.
Can you please insert it.
D. |
|
Tue Nov 10 00:50:47 2020, Dinko Ferencek, POS, POS configuration files created
|
| danek kotlinski wrote: |
| Dinko Ferencek wrote: | pXar parameter files were converted to POS configuration files by executing the following commands on the lab PC at PSI
cd /home/l_tester/L1_SW/MoReWeb/scripts/
python queryModuleLocation.py -o module_locations.txt -f
python prepareDataForPOS.py -i module_locations.txt -p /home/l_tester/L1_DATA/ -m /home/l_tester/L1_DATA/WebOutput/MoReWeb/FinalResults/REV001/R001/ -l /home/l_tester/L1_DATA/POS_files/Folder_links/
cd /home/l_tester/L1_SW/pxar2POS/
for i in `cat /home/l_tester/L1_SW/MoReWeb/scripts/module_locations.txt | awk '{print $1}'`; do ./pxar2POS.py -m $i -T 50 -o /home/l_tester/L1_DATA/POS_files/Configuration_files/ -s /home/l_tester/L1_DATA/POS_files/Folder_links/ -p /home/l_tester/L1_SW/MoReWeb/scripts/module_locations.txt; done
The POS configuration files are located in /home/l_tester/L1_DATA/POS_files/Configuration_files/ |
Dinko
I have finally looked more closely at the file you have generated. They seem fine exept 2 points:
1) Some TBM settings (e.g. pkam related) differ from P5 values.
This is not a problem since we will have to adjust them anyway.
2) There is one DAC setting missing.
This is DAC number 13, between VcThr and PHOffset.
This is the tricky one because it has a different name in PXAR and P5 setup files.
DAC 13: PXAR-name = "vcolorbias" P5-name="VIbias_bus"
its value is fixed to 120.
Can you please insert it.
D. |
Hi Danek,
I think I implemented everything that was missing. The full list of code updates is here.
Best,
Dinko |
|
Tue Jan 19 15:12:12 2021, Dinko Ferencek, POS, POS configuration files created
|
M1560 in position bpi_sec1_lyr1_ldr1_mod3 was replaced by M1613.
The POS configuration files were re-generated and placed in /home/l_tester/L1_DATA/POS_files/Configuration_files/.
The old version of the files was moved to /home/l_tester/L1_DATA/POS_files/Configuration_files_20201110/. |
|
Mon Jan 25 13:03:22 2021, Dinko Ferencek, POS, POS configuration files created
|
The output POS configuration files has '_Bpix_' instead of '_BPix_' in their names. The culprit was identified to be the C3 cell in the 'POS' sheet of Module_bookkeeping-L1_2020 Google spreadsheet which contained 'Bpix' instead of 'BPix' which was messing up the file names. This has been fixed now and the configuration files regenerated.
The WBC values were also changed to 164 for all modules using the following commands
cd /home/l_tester/L1_SW/pxar2POS/
./pxar2POS.py --do "dac:set:WBC:164" -o /home/l_tester/L1_DATA/POS_files/Configuration_files/ -i 1
This created a new set of configuration files with ID 2 in /home/l_tester/L1_DATA/POS_files/Configuration_files/.
The WBC values stored in ID 1 were taken from the pXar dacParameters*_C*.dat files and the above procedure makes a copy of the ID 1 files and overwrites the WBC values. |
|
Wed Mar 18 15:23:27 2020, Andrey Starodumov, General, New rules at PSI
|
From today only two persons from the group allowed to be present. We are working in shifts: Urs in the morning start full qualification and I in the afternoon test HDIs, run Reception, glue caps and switch the cold box, chiller etc after the full test finished.
Silvan is building usually 4 modules and 6-8 HDIs per day.
|
|